



Analyzing C or C++ code requires - in addition to the source code - the configuration that is used to build the code. At SonarSource, we have provided a tool to automate the extraction of this information, the build wrapper.
This tool has been used successfully with many projects, yet there are cases where it does not work well, or where it works correctly but is cumbersome. We recently introduced another way to configure your analysis, the compilation database. The goal of this post is to explain in more detail the pros and cons of each option, and to help you select the one that will be best in your situation, for your projects.
Why is this needed in the first place?
Analyzing source code is made up of many steps, and the first step is the same as for compiling source code: read the source files and build an internal representation of the code. This step depends on some configuration that is usually not present in the source code itself, but in external files (project files or header files) as well as in non-explicit forms (the environment variables on the build machine, the version of some system libraries installed by default…).
What makes C and C++ different?
At the time of writing this article, we analyze 27 languages at SonarSource, and most of them don’t require accurate configuration information. In Javascript, for example, each file can pretty much be analyzed in total isolation, without considering configuration. In Java, some class paths are required for detecting issues that depend on the prototype of the function being called, but many rules can still provide accurate results without this information.
Unfortunately, for C and C++ the situation is quite different. These languages heavily depend on a preprocessor to assemble files, or to select among variants of a program co-existing within a unique source code. And in turn, this preprocessor heavily depends on some external configuration (most importantly, macro definitions and include paths).
Without this configuration, the code will not only miss some details, it might not even look like C at all. I’ve already encountered some code (obviously written by a developer with a Pascal background), that looked like this:
procedure Print(int i)
begin
printf("%d", i);
end
Does it look like C to you? It does, when you know that this user had defined some macros:
#define begin {
#define end }
#define procedure void
And so the code really was identical to:
void Print(int i)
{
printf("%d", i);
}
Even without considering such corner cases, macros usually control which header files get included, and that in turn defines how other macros should be expanded, which in turn can totally change the meaning of the source code.
So, what configuration is needed?
During a normal development process, the configuration usually comes from two sources:
- Some files that describe the configuration of a project (
CmakeLists.txt, Makefile, .vcxproj…) - The way the build machine is installed before the build starts (some files are in some folders, some environment variables are defined)
How to handle machine-level configuration?
There could be more advanced ways to deal with machine-level configuration. We chose a very pragmatic one: We require that the analysis runs in the same environment as the build. That way, any file that was accessed during the build (including files generated during the build) is available when performing the analysis. And all access rights, environment variables, disk mounts… are identical.
How to handle project-level configuration?
We could write tools capable of understanding some project files, or tools working as plug-ins inside build systems. This is what we do for Java, with Maven and Gradle extensions. And with C# with an MsBuild extension. But the problem with C and C++, as always, is that there is not one standard build system, but many different systems, and that many large projects will use a combination of several of them.
The next sections are going to go into more detail for the two options we implemented to get that configuration.
The old and trusted way: Build wrapper
There is only one time when we can be confident that the configuration information is accurately computed: When building a project. The problem is that this configuration is not readily available for us, it is targeted at the compiler (and transferred as command-line options). But this issue can be overcome in most cases. This is where the build wrapper comes in.
The goal of this program is to eavesdrop on the build process, detect every time a compiler is launched, and record the arguments it was invoked with.
Shortcomings
This process of eavesdropping may seem simple, but it is not really. We have to eavesdrop not only on the main build process, but also on all the other processes directly or indirectly started by that process (build tools usually spawn an impressive process tree), across the three operating systems we support. With the wealth of build tools available to the C and C++ communities, there are some cases where this fails:
- On Linux & macOS, the build wrapper relies on dynamic libraries to inject the eavesdropping code into the build processes. If those processes are statically linked, this option is not available.
- Some build systems (for instance, Bazel) copy the source files to a different location and compile them there, in order to provide a sandboxed environment. This means that the files that are actually analyzed are not part of the source tree that was checked out from the SCM, and may not be indexed by the scanner. In the best case the analysis will work, but will not contain source control information (the files actually used are not under source control). In the worst case, those files will be skipped by the analysis, leading to an empty analysis.
- The build wrapper can only eavesdrop on processes started as subprocesses of the build entry-point. If this entry point is communicating with a daemon that was already running (a typical case would be for distributed builds), the build wrapper will be totally ignorant of whatever this daemon does.
These situations aren't common, and when they do occur, it’s usually possible to use a switch that enforces a more basic strategy that will be compatible with the build wrapper. However, this comes with a cost, for instance replacing a distributed build with a slower local build.
The need for a clean build
Since the build wrapper eavesdrops on the compiler processes, if an incremental build detects that a file does not need to be recompiled, it will not spawn a compiler process, and the file will be unknown to the build wrapper.
You may think this is not really a problem. This file will not be analyzed, but since it was unchanged, the results from the previous analysis can be re-used. Unfortunately, this is not the case: When a previously analysed file is no longer mentioned in a subsequent analysis, this is interpreted by SonarQube Server/SonarCloud to mean that it has been removed by the user from the source code. As a consequence, the list of files to analyze must always be complete:
The build wrapper depends on wrapping a full build, not an incremental one.
If you’re accustomed to working with large C or C++ codebases, you know that the ability to do incremental builds is of the essence to be able to achieve reasonable build performance. Does the previous statement mean that you have to give up incremental builds in your CI in order to be able to analyze your code?
Well, yes… And, thankfully, no!
You always need to run a full build, but the launched compiler processes don’t have to do anything on files that are already up-to-date. If you use a tool like ccache, this tool will masquerade as a compiler executable, but will fetch a previously built artifact when asked to build something that is already in the cache, instead of going through the costly process of re-generating this artifact from scratch.
It’s a full build from the outside, but an incremental build from the inside.
By the way, the analysis itself has a built-in mechanism similar to ccache, that can really speed up the analysis as long as you can provide an up-to-date analysis cache.
If, in your situation, using something similar to ccache is not an option, and the cost of performing a full build is an issue, you might want to have a look at the next section.
The newfangled: Compilation database
As we previously noted, there is no unique build system for C++. Nevertheless, there is a de facto standard that emerged a few years ago to describe the result of executing a build. It is called a compilation database. It is not a high-level description of the build rules and dependencies, but the low-level results of what needs to be done in the end, what file needs to be compiled with what option. The same level of information that is generated when the build wrapper eavesdrops on a real build.
The point is that our tools are not the only ones that need this kind of information: Any tool that deals with C or C++ source code needs it, and this compilation database format can be a bridge between build systems and many tools (IDEs, code navigation, documentation…), including our analysis tools.
How to generate it?
There are many ways to generate this data. Some are more robust than others.
For instance, if you are using cmake to build your project, you can invoke it with:
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=ON
And a compilation database will be generated.
There are many other tools that can generate it. Have a look at this rather comprehensive list, and if you still cannot find something that fits what you want in this list, you can also manually generate this file yourself.
Are there any caveats?
Yes, of course. Working with a compilation database offers more flexibility, but this flexibility comes with some added complexity, and some risks of an incorrect configuration, and therefore an incorrect analysis. In the tradition of C and C++, by allowing you to configure analysis from a compilation database, we give you a powerful tool, one that is fully capable of blowing your whole leg off.
When configuring analysis with a compilation database, it should be:
Complete: It should mention all files that are part of the project, even files that have not changed for a long time,
Truthful: All files should have the same options as for a real build,
Self-sufficient: If some files are generated during the build and referenced (directly or not) by the compilation database, we will need them during analysis. This means that even if you configure analysis with a compilation database, enough of the build should be run that the generated files are present for analysis (or are retrieved from some cache),
Up-to-date: If the project changes, the compilation database needs to be updated.
Additionally, a compilation database does not record environment variables, so if your build process temporarily sets some of them, and the compilation depends on them, a compilation database might not be suitable.
Which one should I use?
The short answer is: It depends.
For a more detailed answer, we suggest you follow this decision tree:

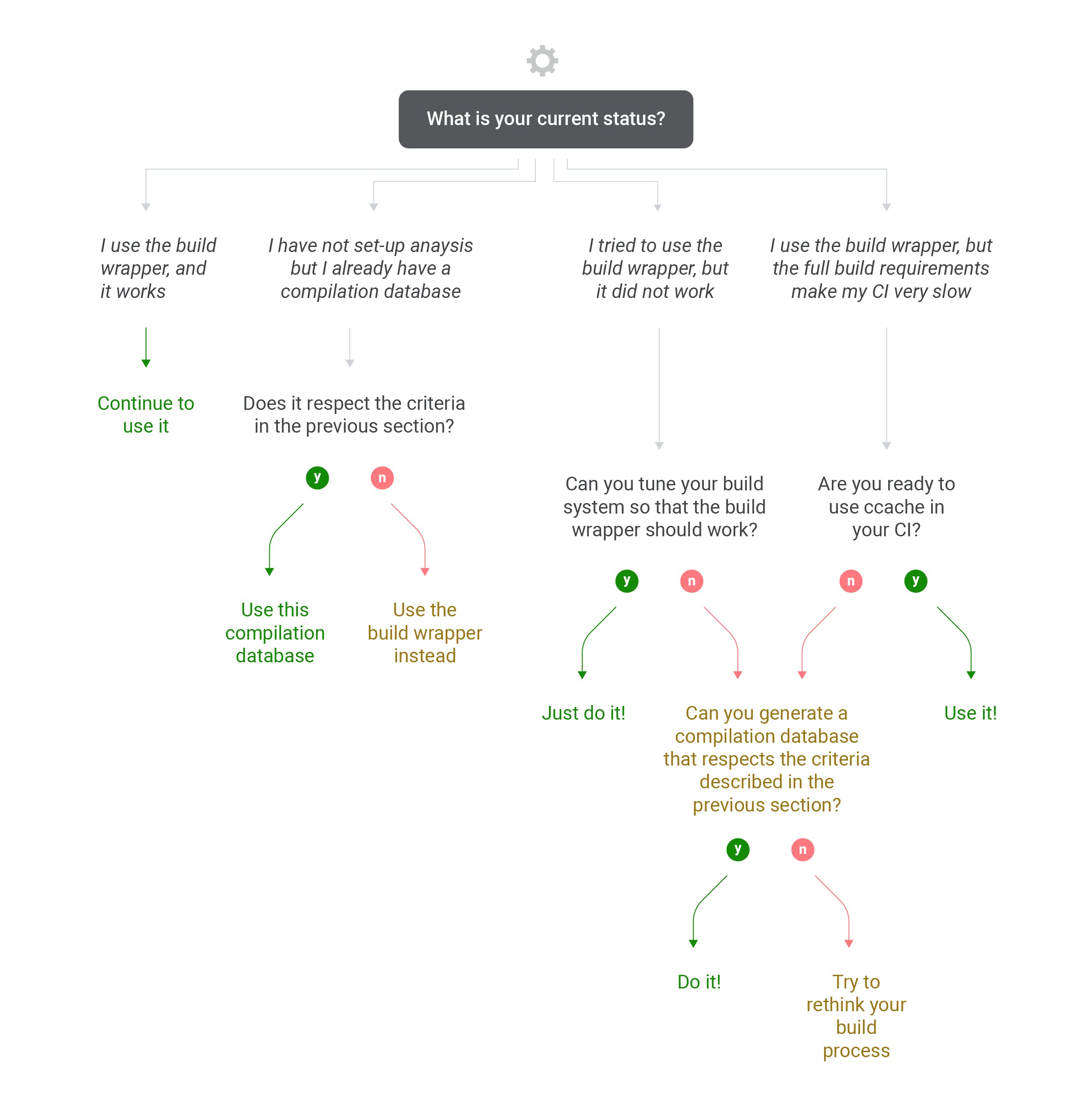
If you are still unsure, or have a feeling that the solution you’ve reached is not optimal, please come and present your situation on our community forum, we’ll be happy to flesh out a solution with you.